// Define a structure named `List` containing a `Vec`. structList(Vec<i32>);
impl fmt::Display for List { fnfmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // Extract the value using tuple indexing, // and create a reference to `vec`. let vec = &self.0;
write!(f, "[")?;
// Iterate over `v` in `vec` while enumerating the iteration // count in `count`. for (count, v) in vec.iter().enumerate() { // For every element except the first, add a comma. // Use the ? operator to return on errors. if count != 0 { write!(f, ", ")?; } write!(f, "{}: {}", count, v)?; }
// Close the opened bracket and return a fmt::Result value. write!(f, "]") } }
fnmain() { let v = List(vec![1, 2, 3]); println!("{}", v); }
structlist_headtasks; /* * ptrace_list/ptrace_children forms the list of my children * that were stolen by a ptracer. */ structlist_headptrace_children; structlist_headptrace_list;
structmm_struct *mm, *active_mm;
/* task state */ structlinux_binfmt *binfmt; long exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ /* ??? */ unsignedlong personality; unsigned did_exec:1; pid_t pid; pid_t tgid; /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->parent->pid) */ structtask_struct *real_parent;/* real parent process (when being debugged) */ structtask_struct *parent;/* parent process */ /* * children/sibling forms the list of my children plus the * tasks I'm ptracing. */ structlist_headchildren;/* list of my children */ structlist_headsibling;/* linkage in my parent's children list */ structtask_struct *group_leader;/* threadgroup leader */
unsignedlong ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ /* * current io wait handle: wait queue entry to use for io waits * If this thread is processing aio, this points at the waitqueue * inside the currently handled kiocb. It may be NULL (i.e. default * to a stack based synchronous wait) if its doing sync IO. */ wait_queue_t *io_wait; /* i/o counters(bytes read/written, #syscalls */ u64 rchar, wchar, syscr, syscw; #if defined(CONFIG_BSD_PROCESS_ACCT) u64 acct_rss_mem1; /* accumulated rss usage */ u64 acct_vm_mem1; /* accumulated virtual memory usage */ clock_t acct_stimexpd; /* clock_t-converted stime since last update */ #endif #ifdef CONFIG_NUMA structmempolicy *mempolicy; short il_next; #endif };
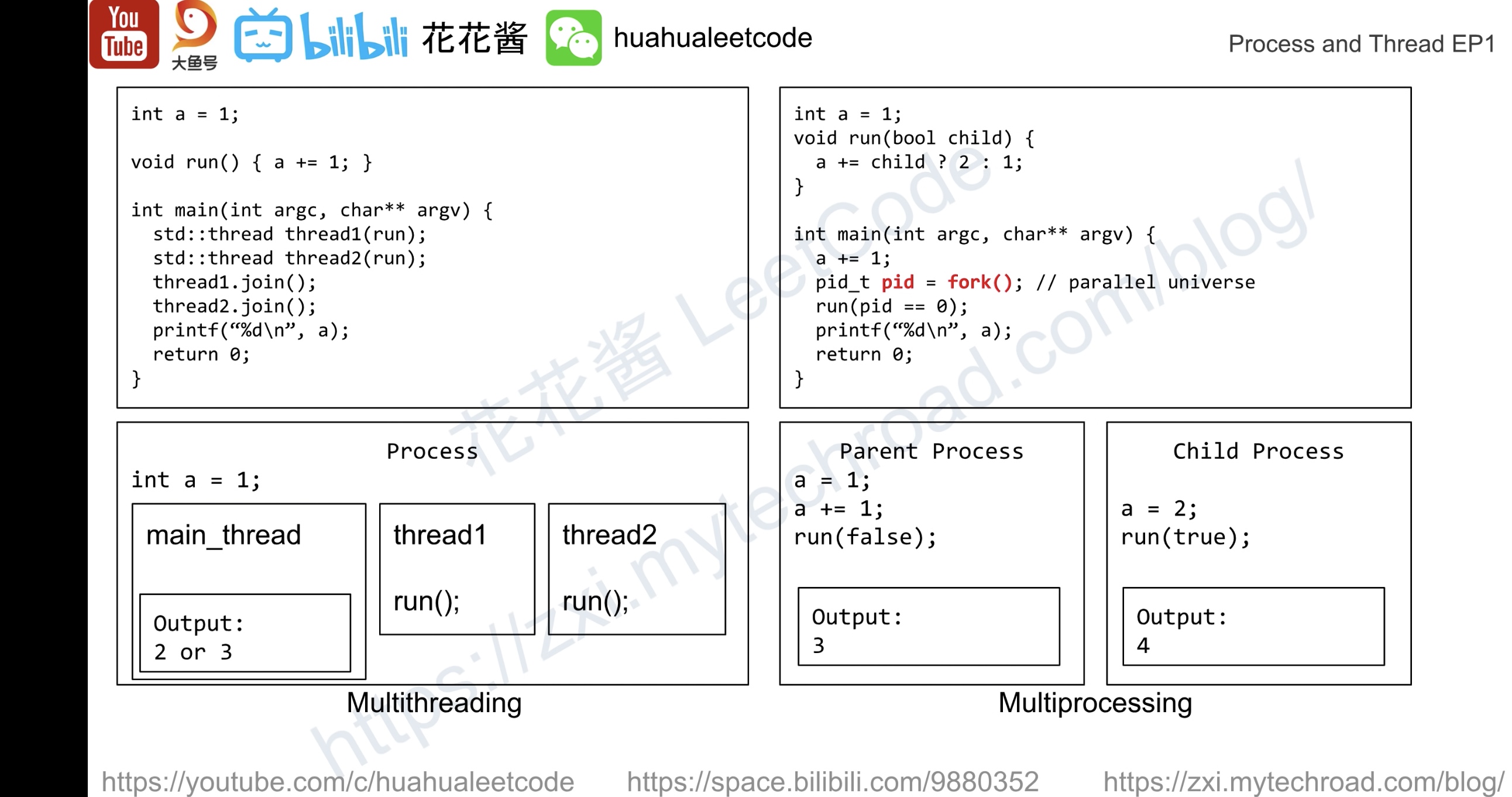
Linux has a unique implementation of threads: It does not differentiate between threads and processes. To Linux, a thread is just a special kind of process.
对 linux 来说 ,thread 和 process 并没有区别。 thread 只是特殊的 process
On modern operating systems, processes provide two virtualizations: a virtualized processor and virtual memory. The virtual processor gives the process the illusion that it alone monopolizes the system, despite possibly sharing the processor among hundreds of other processes.
Chapter 4, “Process Scheduling,” discusses this virtualization.
Virtual memory lets the process allocate and manage memory as if it alone owned all the memory in the system.
Virtual memory is covered in Chapter 12, “Memory Management.”
The task_struct is a relatively large data structure, at around 1.7 kilobytes on a 32-bit machine. This size, however, is quite small considering that the structure contains all the information that the kernel has and needs about a process. The process descriptor contains the data that describes the executing program—open files, the process’s address space, pending signals, the process’s state, and much more.
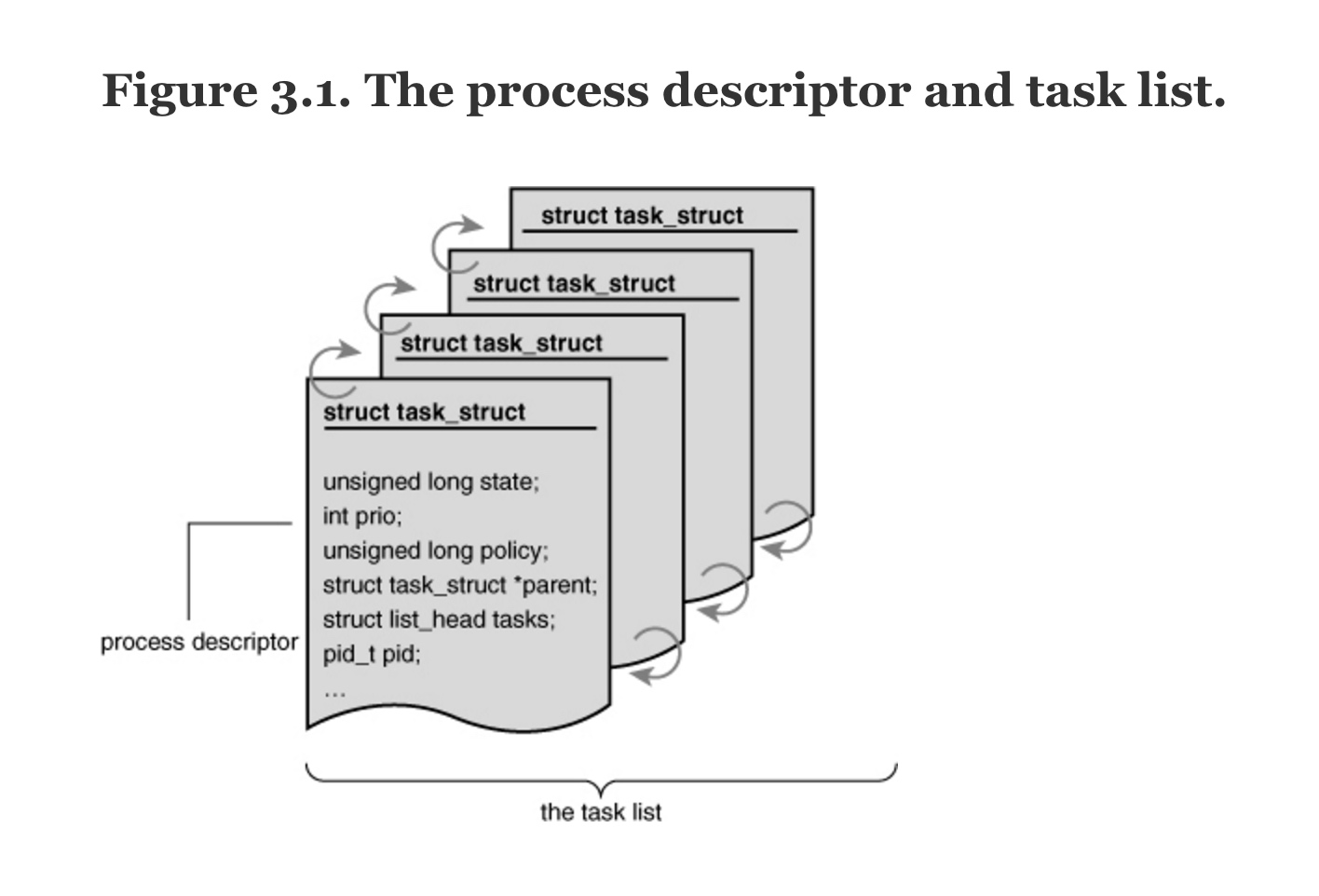
The kernel stores the list of processes in a circular doubly linked list called the task list.
在kernel中 进程描述符存储在环形双向链表(task list)中。
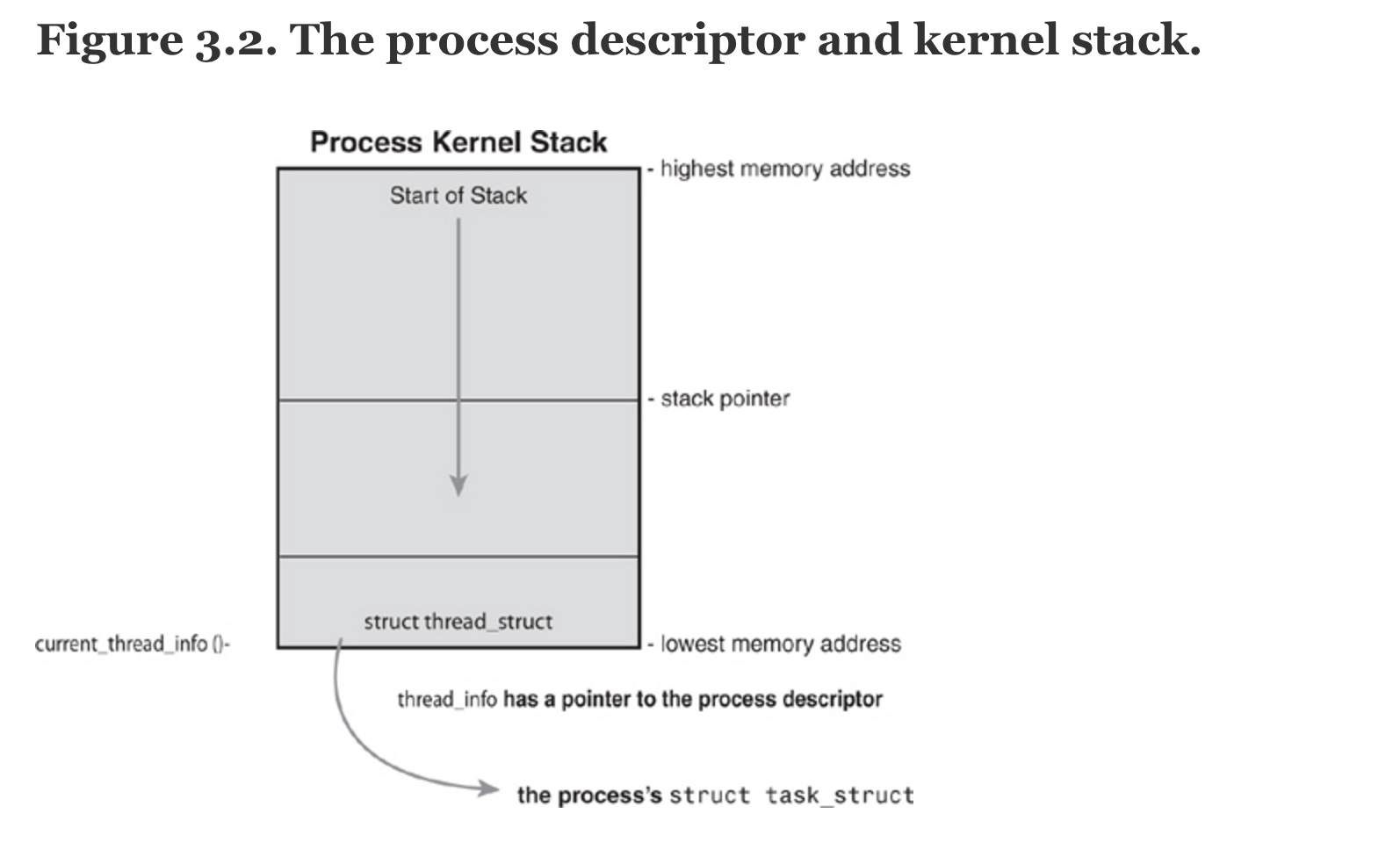
进程描述符 process descriptor ,定义在 <linux/sched.h> 在 Understanding the Linux kernel 笔记(三) 第三章 进程 有贴出pd全部的定义 进程描述符在kernel的栈空间中所在的位置
The system identifies processes by a unique process identification value or PID.
PID 有个默认的最大值 32768
this is controlled in <linux/threads.h>
1 2 3 4 5 6 7 8 9
/* * This controls the default maximum pid allocated to a process */ #define PID_MAX_DEFAULT 0x8000
/* * A maximum of 4 million PIDs should be enough for a while: */ #define PID_MAX_LIMIT (sizeof(long) > 4 ? 4*1024*1024 : PID_MAX_DEFAULT)
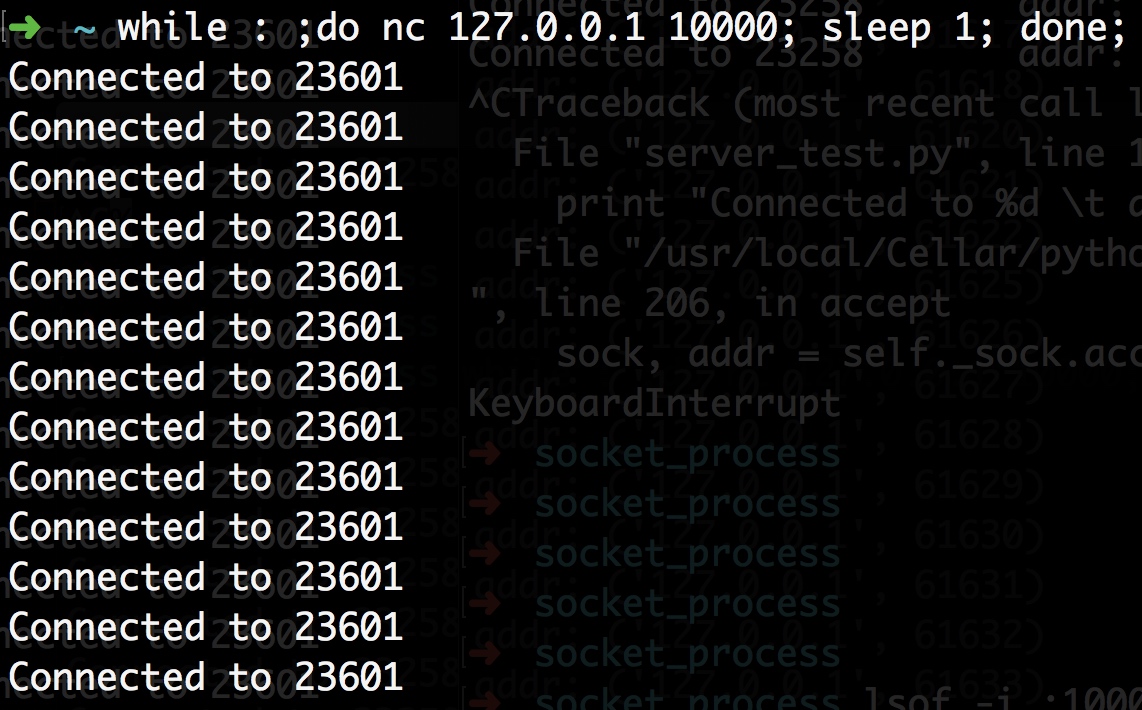
the administrator may increase the maximum value via /proc/sys/kernel/pid_max
PID 最大值可通过改变 /proc/sys/kernel/pid_max 修改
1 2
# cat /proc/sys/kernel/pid_max 32768
x86 架构不能将 当前运行的process 的 PD 存在寄存器中,因为它的寄存器太少了,但是 ppc 架构的可以 ,ppc 架构的寄存器多。
所以还是IBM厉害,寄存器都给的这么奢侈~~
Contrast this approach with that taken by PowerPC (IBM’s modern RISC-based microprocessor), which stores the current task_struct in a register. Thus, current on PPC merely returns the value stored in the register r2. PPC can take this approach because, unlike x86, it has plenty of registers. Because accessing the process descriptor is a common and important job, the PPC kernel developers deem using a register worthy for the task.
x86 架构存储的是 thread_info <The thread_info structure is defined on x86 in <include/asm-x86_64/thread_info.h>>
1 2 3 4 5 6 7 8 9 10 11 12
structthread_info { structtask_struct *task;// a point to pd /* main task structure */ structexec_domain *exec_domain;/* execution domain */ __u32 flags; /* low level flags */ __u32 status; /* thread synchronous flags */ __u32 cpu; /* current CPU */ int preempt_count;
• TASK_UNINTERRUPTIBLE—This state is identical to TASK_INTERRUPTIBLE except that it does not wake up and become runnable if it receives a signal. This is used in situations where the process must wait without interruption or when the event is expected to occur quite quickly. Because the task does not respond to signals in this state, TASK_UNINTERRUPTIBLE is less often used than TASK_INTERRUPTIBLE.
This is why you have those dreaded unkillable processes with state D in ps(1). Because the task will not respond to signals, you cannot send it a SIGKILL signal. Further, even if you could terminate the task, it would not be wise because the task is supposedly in the middle of an important operation and may hold a semaphore.
You’re given strings J representing the types of stones that are jewels, and S representing the stones you have. Each character in S is a type of stone you have. You want to know how many of the stones you have are also jewels.
The letters in J are guaranteed distinct, and all characters in J and S are letters. Letters are case sensitive, so “a” is considered a different type of stone from “A”.
Example 1:
1 2
Input: J = "aA", S = "aAAbbbb" Output: 3
Example 2:
1 2
Input: J = "z", S = "ZZ" Output: 0
solution
1 2 3 4 5 6 7 8 9 10 11 12 13
classSolution(object): defnumJewelsInStones(self, J, S): """ :type J: str :type S: str :rtype: int """ count = 0 for item in S: if item in J: count = count + 1 return count
International Morse Code defines a standard encoding where each letter is mapped to a series of dots and dashes, as follows: “a” maps to “.-“, “b” maps to “-…”, “c” maps to “-.-.”, and so on.
For convenience, the full table for the 26 letters of the English alphabet is given below:
Now, given a list of words, each word can be written as a concatenation of the Morse code of each letter. For example, “cab” can be written as “-.-.-….-“, (which is the concatenation “-.-.” + “-…” + “.-“). We’ll call such a concatenation, the transformation of a word.
Return the number of different transformations among all words we have.
1 2 3 4 5 6 7 8 9
Example: Input: words = ["gin", "zen", "gig", "msg"] Output: 2 Explanation: The transformation of each word is: "gin" -> "--...-." "zen" -> "--...-." "gig" -> "--...--." "msg" -> "--...--."
There are 2 different transformations, “–…-.” and “–…–.”.
Note:
1 2 3
1. The length of words will be at most 100. 2. Each words[i] will have length in range [1, 12]. 3. words[i] will only consist of lowercase letters.
这套方案是 Red Hat 的主推的NFV(Network Functions Virtualization)技术标准。 其中 dpdk 主要解决传统 linux 网络协议栈中数据包的传输要经过内核态和用户态的拷贝开销。dpdk的做法是将数据包传输全部放在用户态进行。由Intel提出并开源。主要基于Intel的网卡。
// 写法2 for( int j = i ; j > 0 && arr[j] < arr[j-1] ; j -- ) swap( arr[j] , arr[j-1] ); // 写法3 T e = arr[i]; int j; // j保存元素e应该插入的位置 for (j = i; j > 0 && arr[j-1] > e; j--) arr[j] = arr[j-1]; arr[j] = e; }
return; } intmain(){
int n = 20000; // 测试1 一般测试 cout<<"Test for random array,size = "<<n<<", random range [0, "<<n<<"]"<<endl; int *arr1 = SortTestHelper::generateRandomArray(n,0,n); int *arr2 = SortTestHelper::copyIntArray(arr1, n);
// 测试2 有序性更强的测试 cout<<"Test for more ordered random array, size = "<<n<<", random range [0, 3]"<<endl; arr1 = SortTestHelper::generateRandomArray(n,0,3); arr2 = SortTestHelper::copyIntArray(arr1, n);
资源名称:Toivon tuolla puolen(希望的另一面, The Other Side of Hope) 主要演员:韦勒·维坦恩,卡蒂·奥廷宁,汤米·柯贝拉,什万·哈吉 电影类型:剧情,喜剧 产 地:芬兰,德国 导 演:阿基·考里斯马基 发布时间:2017 豆瓣评分:8 豆瓣链接:https://movie.douban.com/subject/26678509/ 简介:描述叙利亚难民为寻找避难之处来到芬兰赫尔辛基,与当地人结识的过程。
$ git clone git://git.osmocom.org/openpcd.git $ cd openpcd/firmware 设置环境变量(arm-elf-gcc所在目录) $ export PATH=$PATH:/home/mtq/simtrace/arm-elf-toolchain/install/bin $ make -f Makefile.dfu BOARD=SIMTRACE $ make BOARD=SIMTRACE DEBUG=1 TARGET=main_simtrace $ cat dfu.bin main_simtrace.bin > main_simtrace.samba $ cd ../.. 其中生成的文件
dfu.bin – the sam7dfu 2nd level bootloader. It implements the USB DFU (Device Firmware Upgrade) profile. main_simtrace.bin – the actual simtrace program. To be loaded via DFU, using dfu-util. main_simtrace.samba – sam7dfu + simtrace image. to be loaded via SAM-BA, using sam7utils (see below).